Once a Project has been created, the next step is to bring your texts into the application. This is the gateway to analysis, and Error Analyzer is designed to make it as straightforward and reliable as possible.
All imported material is tied to a Project, which ensures that each dataset remains contextually bounded. When you add a new corpus, you provide a name and specify the language of the texts. These parameters are not just labels: they serve as metadata that guide later analysis and make your research transparent and reproducible. For example, if you are working with English essays written by learners at the B1 level, naming the Project accordingly and identifying English as the language provides an immediate frame of reference for both yourself and any collaborators.
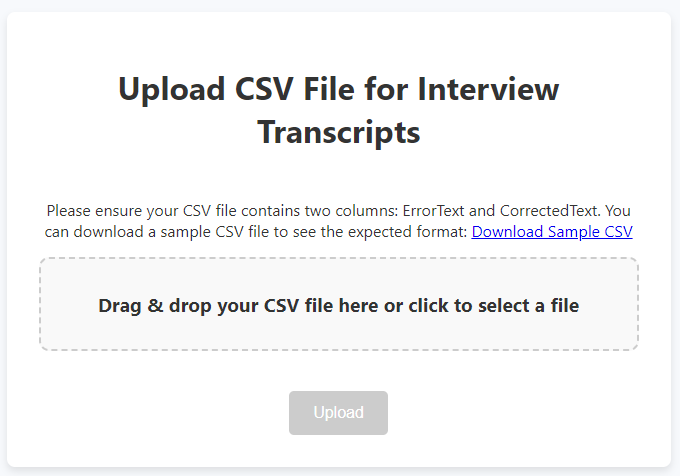
Data is uploaded in the form of a CSV file, which functions as a simple but rigorous format for paired texts. The file must include two columns: one labeled ErrorText, containing the original or erroneous version of each text segment, and one labeled CorrectedText, containing the revised or corrected version. This structure operationalizes the principle of contrastive error analysis by keeping originals and corrections aligned row by row. A single CSV might contain a full set of learner sentences, translation drafts and their revisions, or any other data in which comparison between two versions is central.
For collaboration and preservation, Project Portability is built into the design. At any point, an entire Project can be exported as a .zip archive. This package contains the corpus, annotations, and tagging schema, allowing you to transfer your work to another instance of the application or share it with colleagues. In this way, Error Analyzer supports not only individual research but also team-based workflows, replication studies, and long-term archiving of data.
In addition to export, the application also provides a simple way to bring projects back in. From the homepage, the user clicks Import and selects a .zip archive previously exported from Error Analyzer. The system then restores the entire project, including corpus, annotations, and tagging schema, directly into the workspace. This straightforward process ensures continuity of research, allows colleagues to merge or review shared projects, and supports smooth transitions between different installations of the application.