Annotation is the core of qualitative error analysis, and Error Analyzer provides an environment designed to make this process both systematic and efficient. The annotation workspace presents paired texts side by side, allowing you to move beyond impressionistic comparison and instead work within a structured interface that highlights differences and supports precise classification.
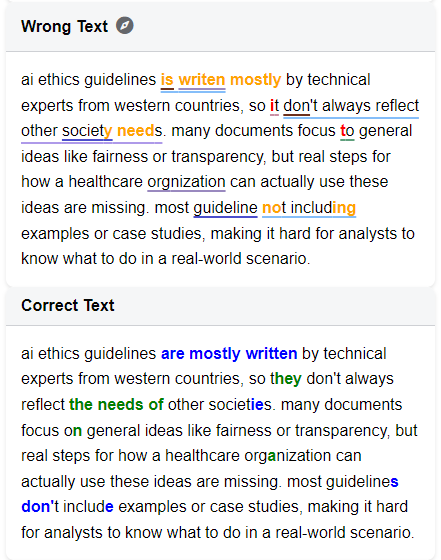
At the center of this workspace is the comparison view. Each pair of texts, the original and the corrected version, is displayed together. A built-in “diff” function highlights additions, deletions, and substitutions at the level of characters, words, or phrases. This makes even subtle changes visible at a glance and ensures that no variation is overlooked.
The system’s flexible tagging framework allows you to construct a hierarchical schema that reflects your research design. Tags can be customized with names, descriptions, and colors, and can be organized into categories and subcategories (for example, Grammar → Tense → Past Tense). This structure supports systematicity: every annotation is tied to a consistent typology, and your entire corpus can be coded according to the same set of analytical categories.
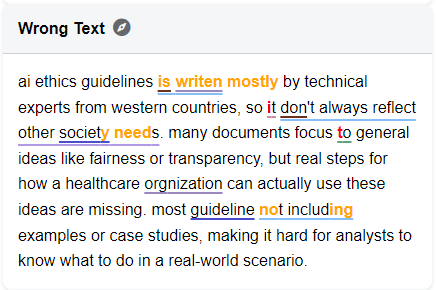
Annotating itself is designed to be intuitive. With a simple point-and-click action, you highlight a segment of text in either the original or the corrected version and assign it the relevant tag. The annotation is immediately rendered as a colored underline, giving you visual feedback and a clear map of how the text has been marked.
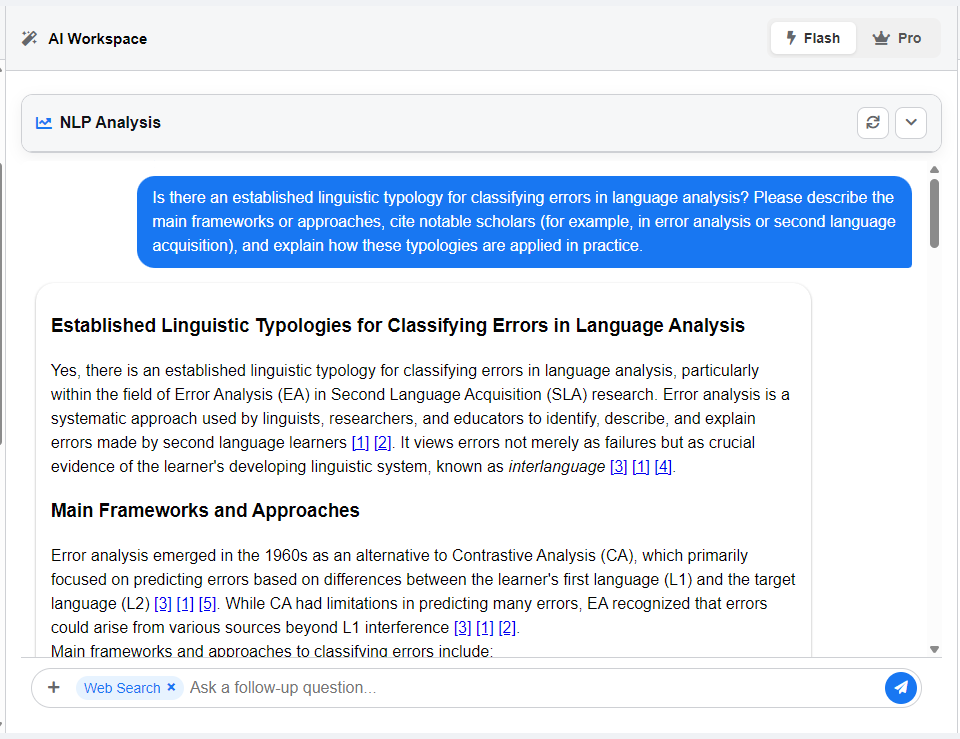
For deeper support, the interface integrates an AI-assisted chat. This feature allows you to interact with the application in real time: you can request suggestions for tagging, ask for clarification about the selected text, or even instruct the system to perform automated tagging based on your schema. While the researcher remains in control of interpretation, the AI component accelerates routine tasks and offers additional perspectives that may sharpen your analysis.
Together, these features turn annotation into a systematic, transparent, and replicable process. Researchers can move from raw differences in text to a structured classification of errors or changes, building a dataset that is ready for interpretation, reporting, and further computational analysis.