Once you have completed the one-time setup of your API key in the Settings page, you are ready to begin your first research project. This section walks you through the workflow inside Error Analyzer, from creating a dedicated workspace to preparing and processing your texts so they are ready for annotation and exploration.
Part 1: Create Your Project Workspace #
Every study begins with a dedicated project. A project in Error Analyzer functions like a laboratory for your dataset, keeping texts, annotations, and notes organized in one controlled environment.
- Navigate to Projects: From the main dashboard, select Projects.
- Create New Project: Click Create New Project.
- Define Your Study: Provide a descriptive name (for example, Verb Form Study – English Learners), write a short description of your research goals, and select the correct language for your texts. Defining the language is crucial, since it ensures the accuracy of the linguistic analysis.
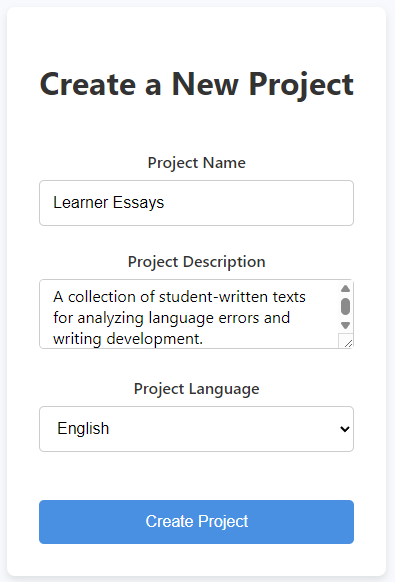
- Confirm: Click Create Project. You will be taken to the dashboard of your new workspace.
Part 2: Prepare Your Text Data (CSV File) #
Error Analyzer works with text pairs provided in a CSV file. You can create this file in Microsoft Excel, Google Sheets, LibreOffice Calc, or any spreadsheet tool.
The file must contain exactly two columns:
- ErrorText: the original version of the text, containing errors or earlier drafts.
- CorrectedText: the revised version of the same text.
Each row represents one pair. For better visibility in the comparison view, it’s recommended that each pair contains two or three short paragraphs at most. This keeps the analysis clear and easy to follow. If needed, you can still include longer texts, but avoid single-sentence pairs whenever possible.
When saving, choose CSV (Comma delimited) (.csv) format.
You can see a good example here: 👉 ai_ethics_paragraph_corrections.csv
Part 3: Upload and Select Your Data #
With your CSV prepared, you can now import it into the project.
- Upload: In your project dashboard, Click on View Project → Drag & drop your CSV file here or click to select a file and select your file.
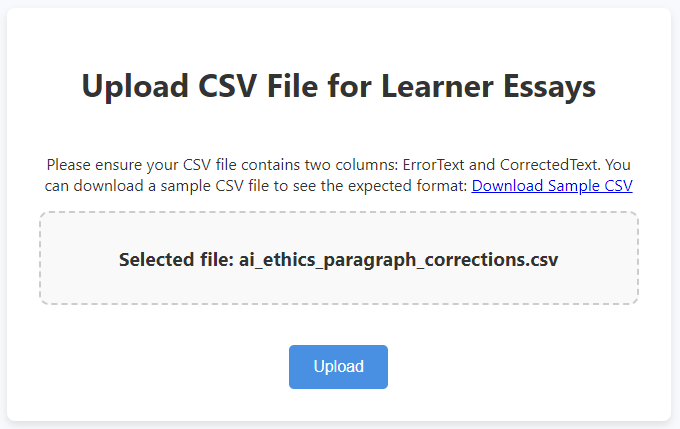
- Review: A list of all text pairs will appear.
- Select: To include the entire dataset, click the first checkbox to Select All. This ensures that every text pair is loaded into the analysis. You may also choose only specific pairs by checking them individually, but this is not recommended unless you have a clear reason to work with a subset of the data.

- Process Data: Click Perform NLP to apply natural language processing to your texts. This step analyzes the corpus and produces the structured information needed for linguistic exploration, such as tokens, parts of speech, and syntactic relations.
Part 4: Processing the Texts (Preparation Phase) #
This step is not yet your analysis but the preparation of linguistic data.
- The application submits your selected texts to the AI engine.
- Sentences are broken into grammatical components (nouns, verbs, adjectives, and so on).
- Relationships between words are mapped, such as subject–verb or verb–object dependencies.
- A linguistic blueprint is created for each text pair, which later supports annotation, tagging, and interpretation.
Depending on the size of your corpus, this may take time. Allow the process to complete without closing the browser tab or navigating away.
Part 5: Success – Your Project Is Ready #
When processing is finished, the application redirects you to the main analysis interface. At this point, the initial NLP pass has been completed. A second round then begins, where the LLM reads the NLP results and builds a detailed report. This may take additional time, so a Loading Analysis message is displayed while the system continues working.

As soon as you arrive on the tagging page, the interface is already interactive. You can navigate between your text pairs, review the color-coded changes (additions, deletions, replacements), and begin preparing annotations. The deeper outputs of the NLP analysis, such as grammatical diagrams and structured data tables, will only appear once the LLM has finished its report.
When the report is ready, your first text pair is displayed in full detail, enriched with:
- Color-coded changes
- Interactive grammatical diagrams
- Structured tables of processed data
From here, your texts are fully prepared. You can begin the core work of exploration, annotation, and discovery, with your linguistic expertise guiding interpretation and theory building.