The deep linguistic analysis in Error Analyzer is not performed locally in your browser. Instead, it relies on resource-intensive AI models running on the backend. To keep the application responsive and to manage API usage efficiently, analyses are generated and retrieved on a per-pair basis.
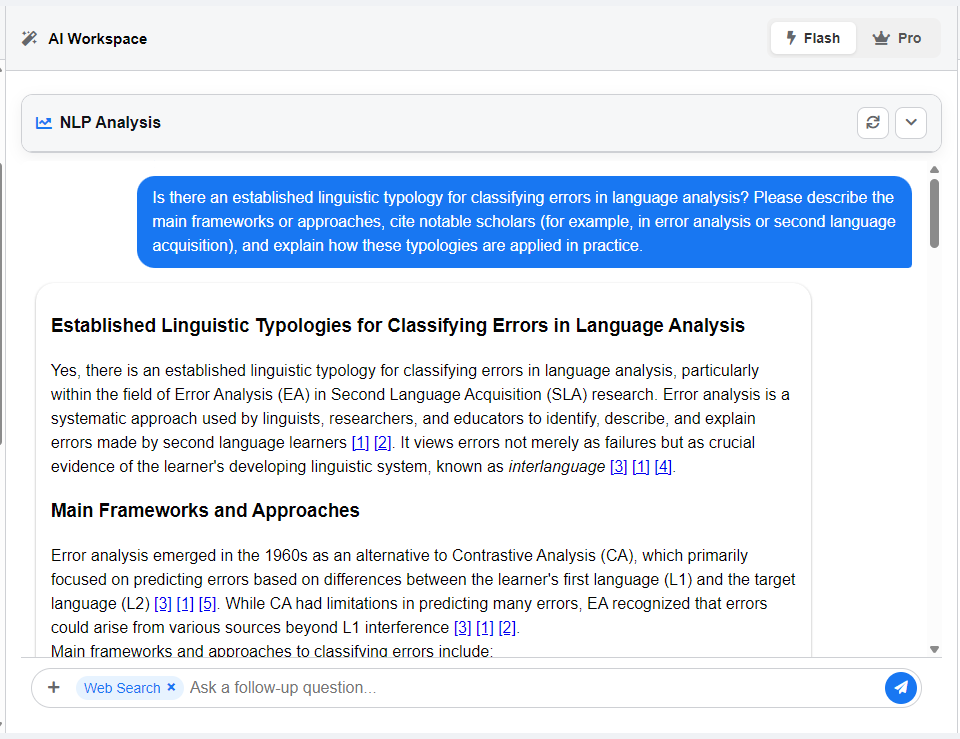
When a New Analysis is Requested #
- Initial Load
When you first open the workspace, the system automatically loads the analysis for the first error pair in your dataset. During this process, you will see a “Loading analysis…” message in the AI Workspace.

- Switching Error Pairs
Every time you select a new pair from the Sources Panel, the system requests and displays the analysis for that specific pair. The AI Workspace will update and show that the data is being loaded. - Manual Refresh
The refresh icon in the top-right corner of the “NLP Analysis” card allows you to re-run the analysis for the currently selected pair. This is useful when a previous attempt failed or when you want to ensure the results reflect the latest AI model updates. - Changing the Language
If you switch the application’s display language, the interface and the analysis results are re-rendered. This action triggers a new analysis request for the active pair so that all generated content appears correctly in the chosen language.
Best Practices to Manage API Requests #
- Be patient after switching pairs. Allow the analysis to finish loading before moving to another pair. Rapid switching cancels ongoing requests and starts new ones, wasting both time and API calls.
- Use refresh deliberately. The refresh button is valuable for obtaining the latest analysis, but each click is a new request. Trigger it only when you have a clear reason to do so.
- Rely on session caching. Once an analysis has been generated for a pair, it is cached during your session. If you revisit that pair, it will reload instantly from memory without another API call. Keep in mind that refreshing the entire browser clears this cache.
Why This Matters #
By treating each analysis as a separate, per-pair operation, the application ensures that heavy computational tasks remain manageable. For researchers, this means smoother navigation through texts, reduced waiting times, and more intentional use of AI resources.