The NLP Analysis is one of the central features of Error Analyzer. Located in the AI Workspace panel, it provides a detailed linguistic breakdown of the Error Text and Corrected Text pairs. This analysis is generated by advanced AI models and is designed to help you examine the nature of errors at a fine-grained level.
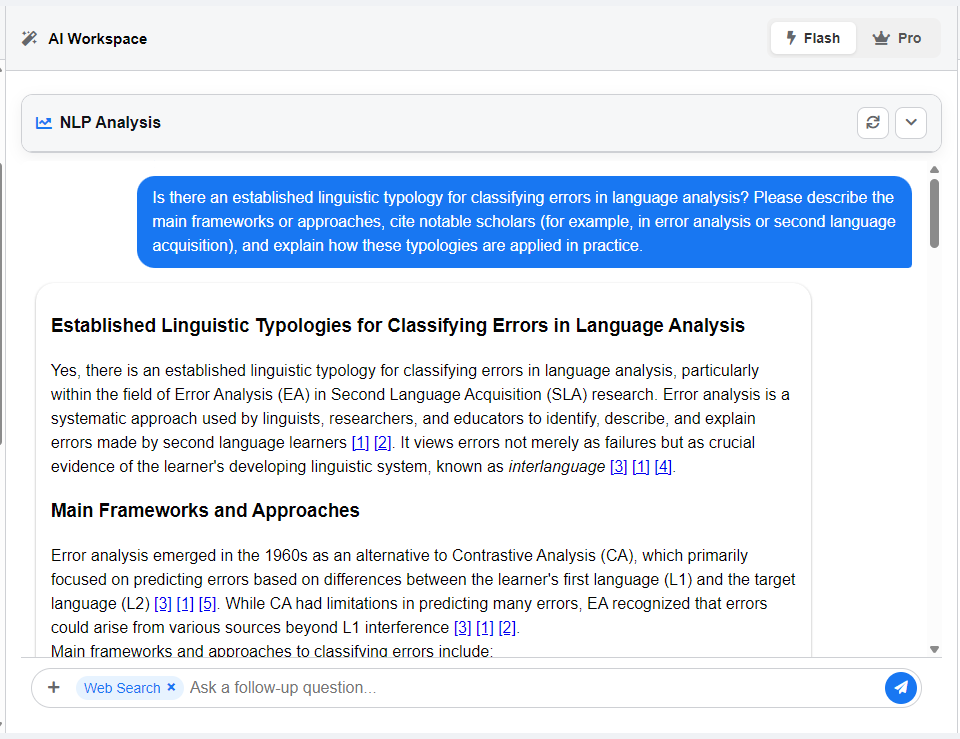
The analysis is displayed through a set of dedicated tabs, each focusing on a different dimension of the texts. Together, these views allow you to move from high-level summaries to detailed linguistic structures, ensuring that both micro-level errors and broader patterns are captured.
The Tabs of the NLP Analysis #
Overview Tab
The starting point of every analysis. Here you find:
- Global Patterns: Recurring linguistic tendencies identified across the text.
- Observations: Concrete, data-backed points about the text.
- Interpretations: Theory-guided insights suggesting reasons for the observed issues.
- Limitations: Notes on ambiguities or areas where the AI model shows low confidence.
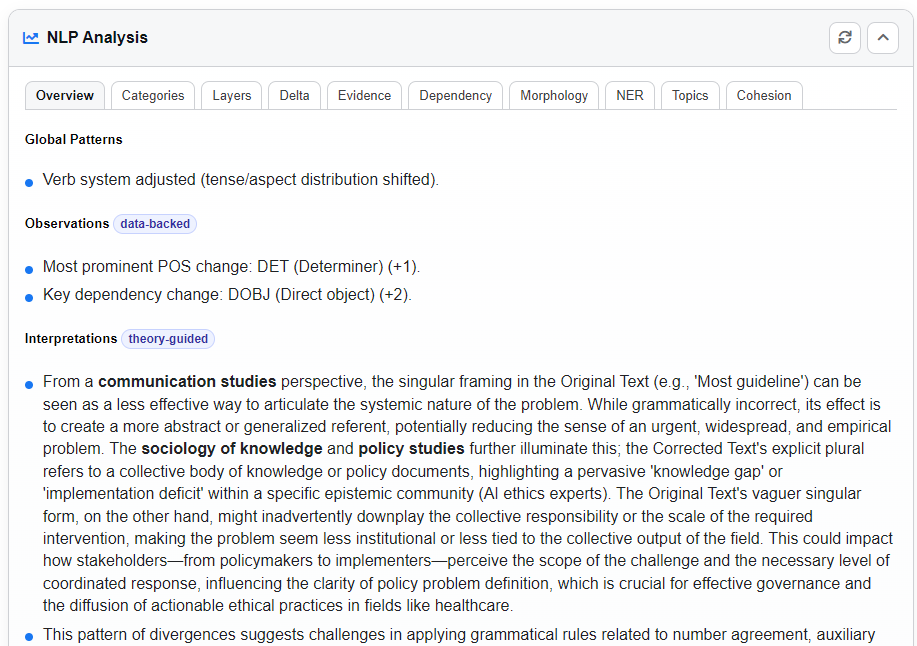
Categories Tab
Groups findings into meaningful categories (e.g., Grammar, Style, Lexicon). Each category provides:
- A name and description.
- A list of specific findings with labels, explanations, and confidence scores.
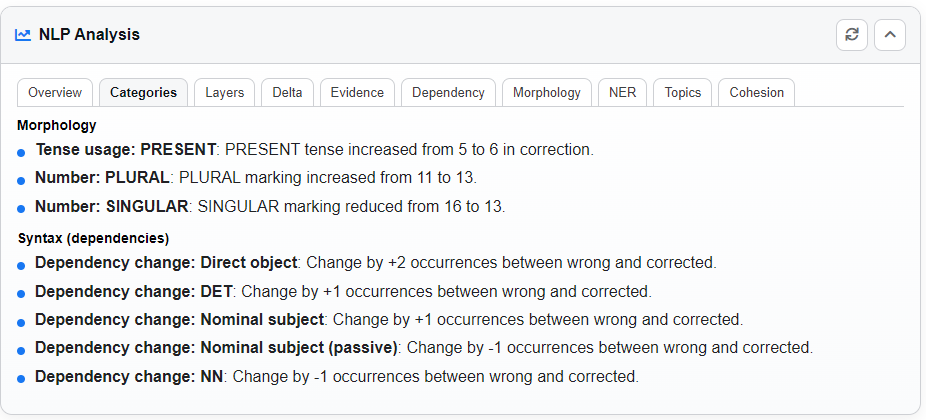
Layers Tab
Organizes findings into broader linguistic layers. For instance, a Syntax layer may include Word Order and Agreement. This helps you see how phenomena interrelate.
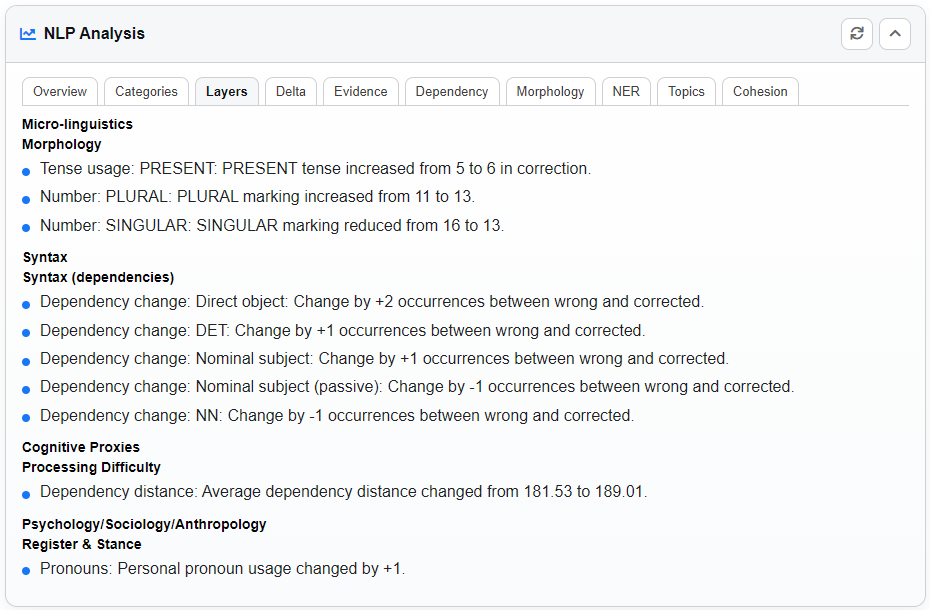
Delta Tab
Compares the Error Text and Corrected Text quantitatively, highlighting what has changed:
- POS Delta: Shifts in parts of speech (e.g., +2 Nouns, –1 Verb).
- Dependency Delta: Changes in grammatical relationships.
- Entities Delta: Gains or losses of named entities.
- Tense Delta: Changes in verb tense distribution.
- Number Delta: Singular vs. plural noun usage.
- Surface Edits: Counts of additions, deletions, and replacements.
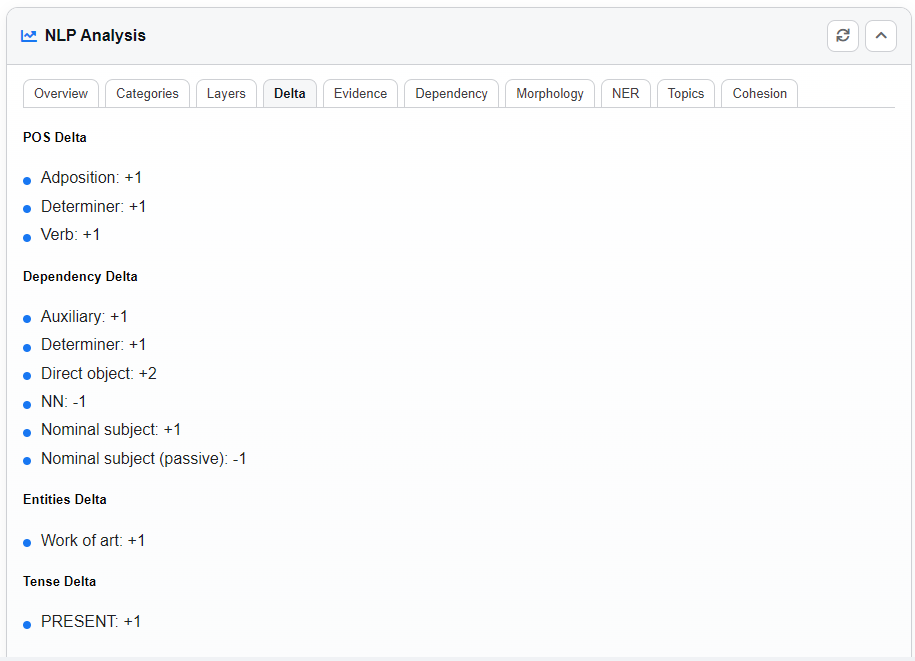
Evidence Tab
Links findings back to specific text tokens. Each piece of evidence includes:
- A short summary.
- Wrong Tokens (from the Error Text).
- Correct Tokens (from the Corrected Text).
Clicking an item highlights the tokens in the Sources panel.
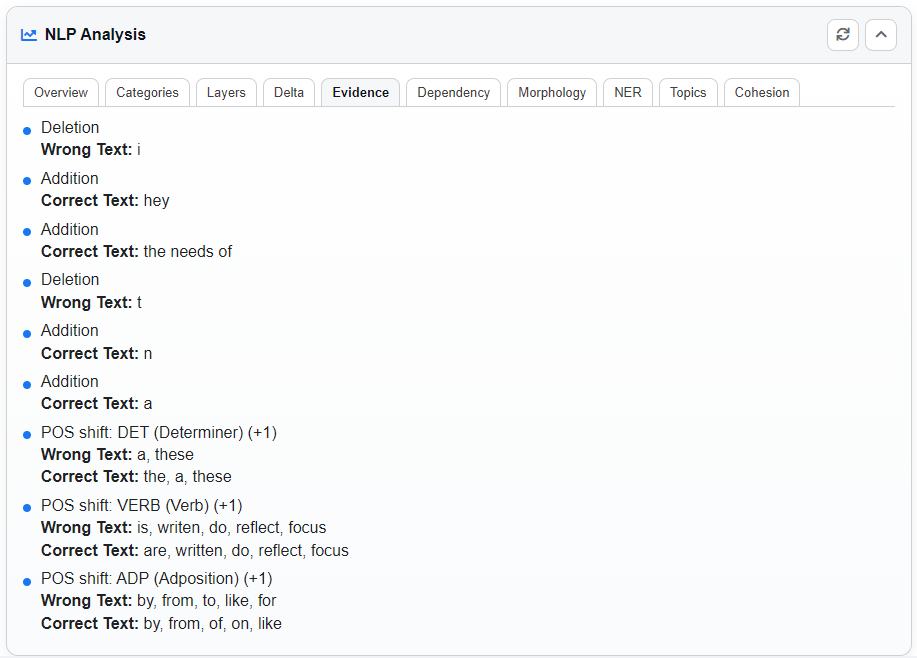
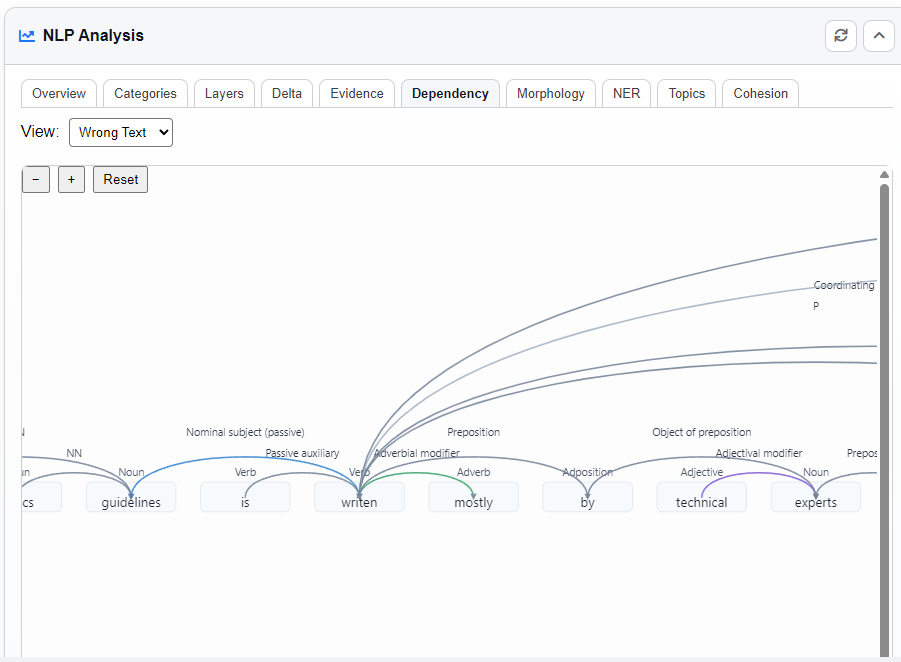
Dependency Tab
Visualizes sentence structure with interactive parse trees. You can:
- Switch between the Error and Corrected texts.
- Hover arcs to inspect grammatical relations.
- Pan and zoom to explore sentence structures.
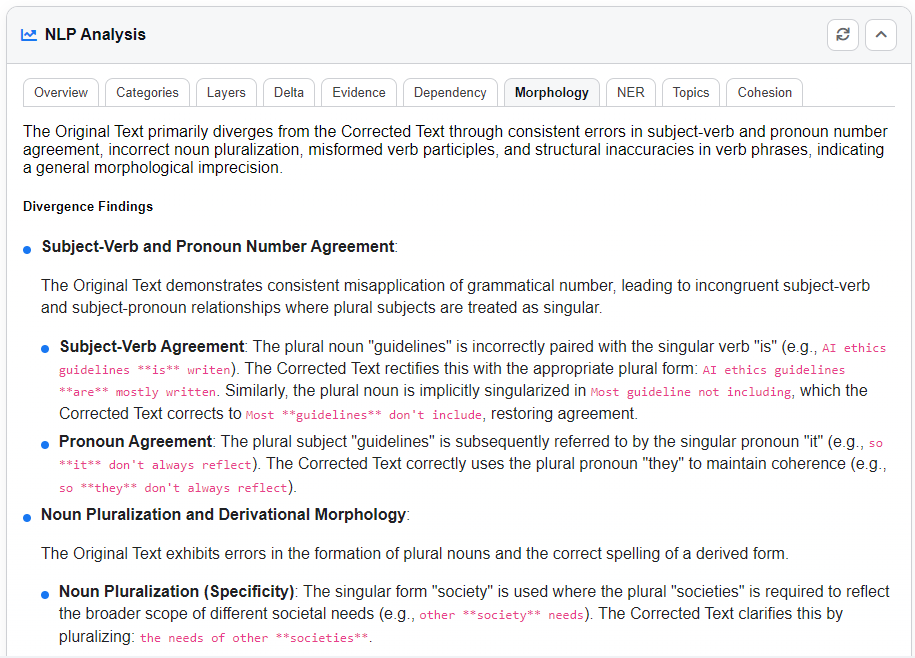
Morphology Tab
Presents a token-by-token breakdown of words in both versions:
- Token, Lemma, and Part of Speech.
- Morphological features (tense, number, person, gender).
This view also highlights morphological differences between the texts.
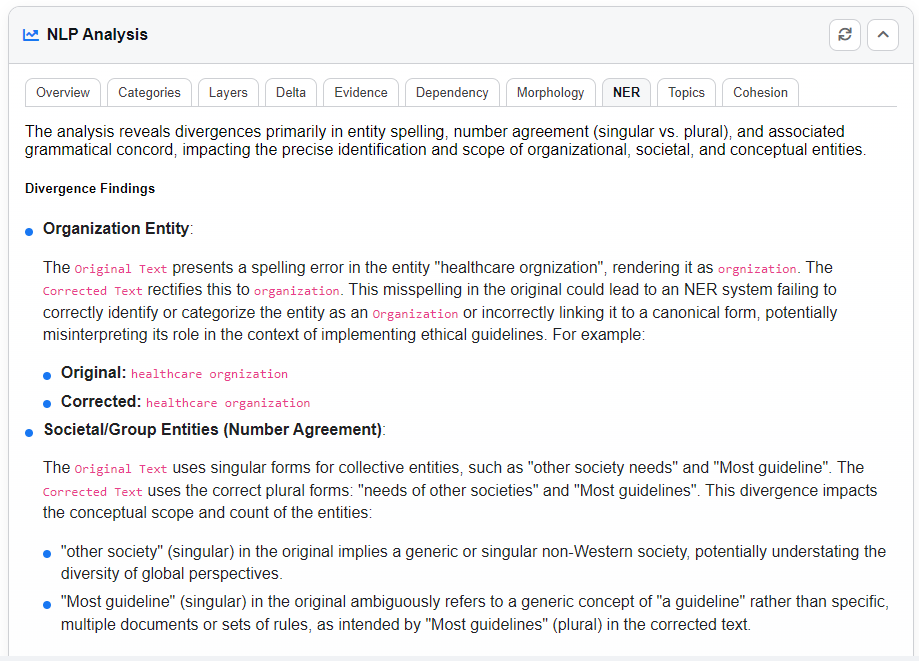
NER (Named Entity Recognition) Tab
Lists all identified entities such as people, places, and organizations. Each entry includes:
- The entity name.
- Its type (e.g., Person, Location).
- The exact text span.
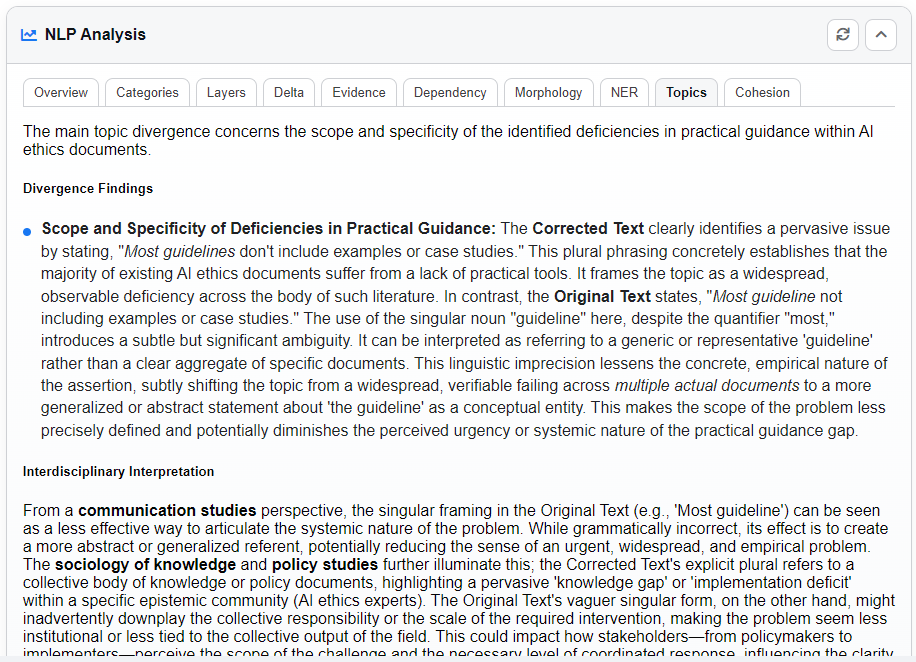
Topics Tab
Identifies the central topics of the texts and highlights divergences between the Error and Corrected versions.
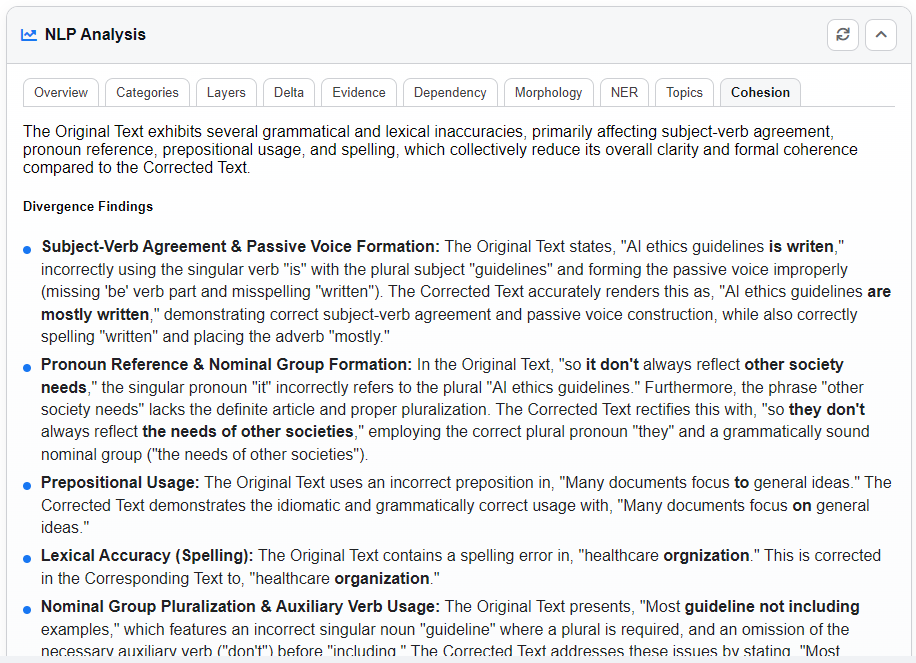
Cohesion Tab
Analyzes how sentences and ideas connect, providing insight into the text’s overall flow and readability.
How to Work with the Tabs #
- Start with the Overview for a high-level sense of the text.
- Move to Categories and Layers for structured detail.
- Use Delta to quantify changes between versions.
- Consult Evidence to ground patterns in specific examples.
- Explore sentence structure in Dependency.
- Inspect individual word features in Morphology and NER.
- Conclude with Topics and Cohesion for big-picture insights.
Why It Matters #
By combining these perspectives, the NLP Analysis allows you to approach your texts systematically. It transforms isolated corrections into structured findings, making it easier to explain error patterns, connect them to linguistic theory, and validate your interpretations.
⚠️ Reminder: While the AI provides detailed analyses, it may occasionally misclassify elements. Always review the output critically and use it as evidence to support, not replace, your expertise.